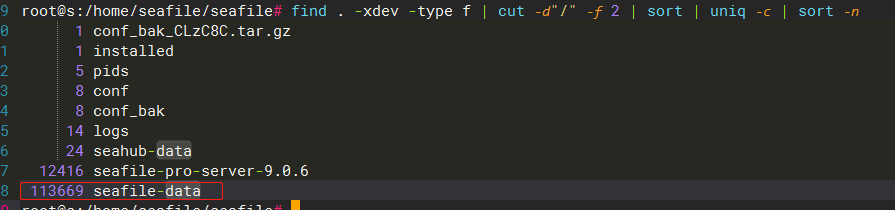
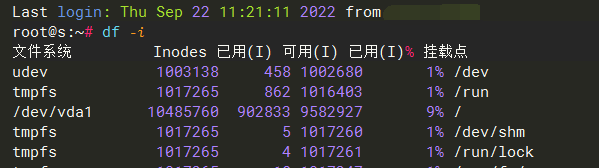
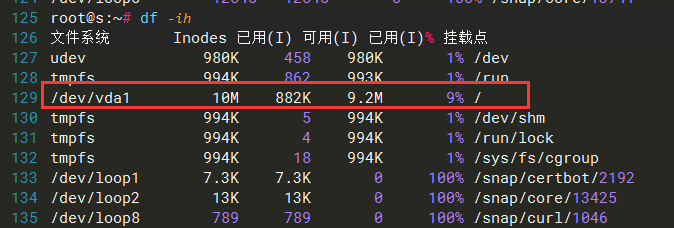
df -i 检查发现
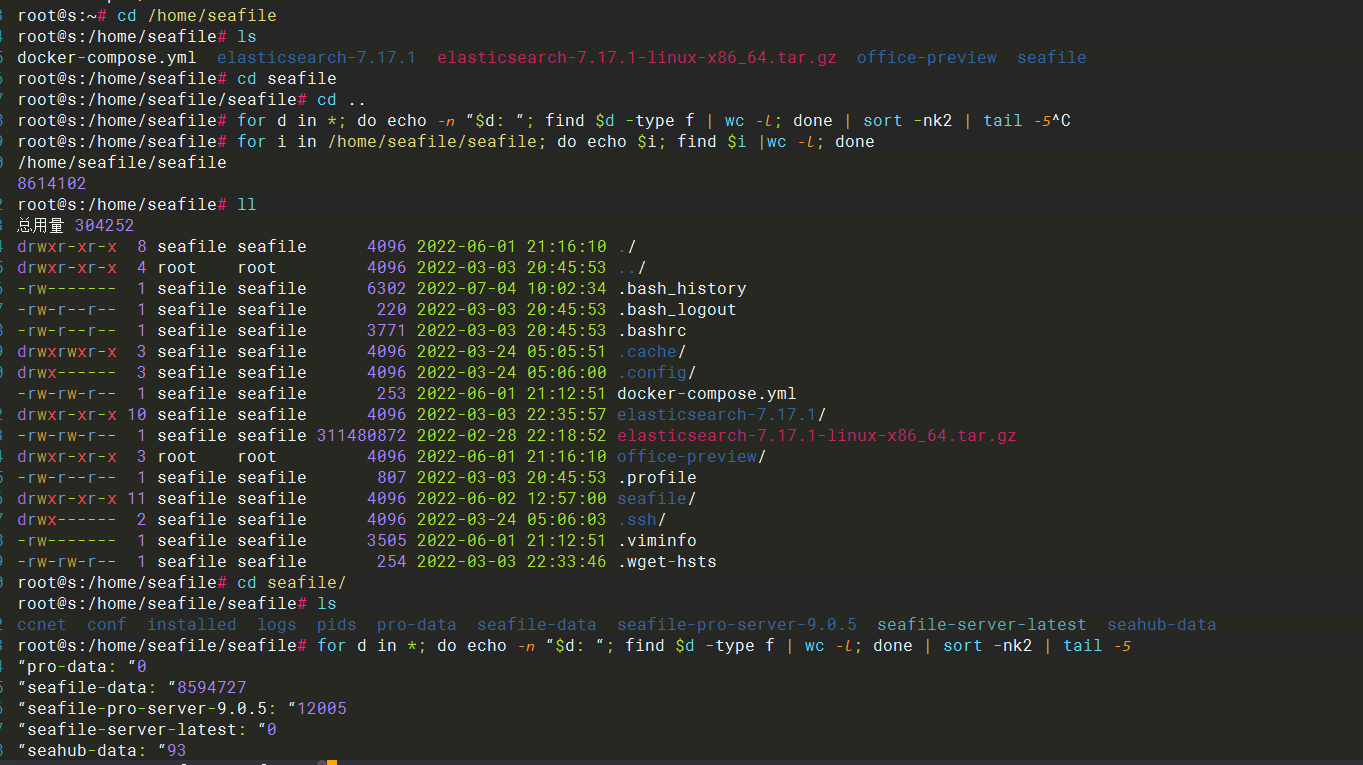
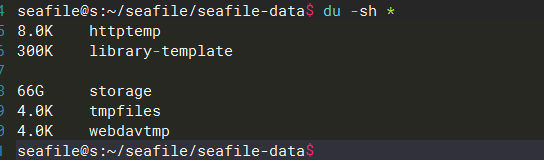
检查 seafile 部署目录 inode 使用量,for i in /home/seafile/seafile; do echo $i; find $i |wc -l; done8614102seafile-data 使用了 8594727
这就很奇怪了,问题是为什么会占用那么多的 inode?
进一步检查
分块存储的目录,竟然用了 8 百万,这还是我一个人使用的服务器,自己并没有频繁使用文件历史、删除大量文件、回收站等功能,并且没有其他用户,我还主动进行了 Seafile GC,因为本身没什么数据,也没什么可以清理,回收站、资料库回收站、版本历史,清的清,关的关,重启了 seafile 服务,情况没有任何改善或减少
这是遇到了 BUG ?没人遇到过此类问题?我下一步该排查什么地方?
这个我该怎么解决?
查到一个在 2015年提的issue,目前看没有任何改善
opened 09:40PM - 08 Jul 15 UTC
closed 07:29AM - 13 Aug 15 UTC
After finding I ran out of available inodes on my virtual machine, I found out s… eafile is using up most of them (using `find / -xdev -printf '%h\n' | sort | uniq -c | sort -k 1 -n`).
I had one large-ish (6GB) library which I just almost completely emptied (for debugging purposes), I set the history setting to **Don't keep history** and ran `seaf-gc.sh run` multiple times on the server.
This is the output for this library:
`[07/08/15 23:31:30] gc-core.c(350): GC finished. 9 blocks total, about 9 reachable blocks, 0 blocks are removed.`
Which is satisfying, I came from ~90.000 blocks when the library was still full-size.
Still, the `seafile-data/storage/fs/{LIBRARY_ID}/{XX}` directories (258 of them) take up some 1.6GB and ~400.000 inodes (count using `ls -Ria | sed -e 's/^ *//' -e 's/ .*//' -e '/^$/d' -e '/^\./d' | sort -u | wc -l`).
This is an absurd amount of files for an empty library, is there any way to clean this up?
**EDIT:** Also, the seaf-cli client has the same problem for the same library.
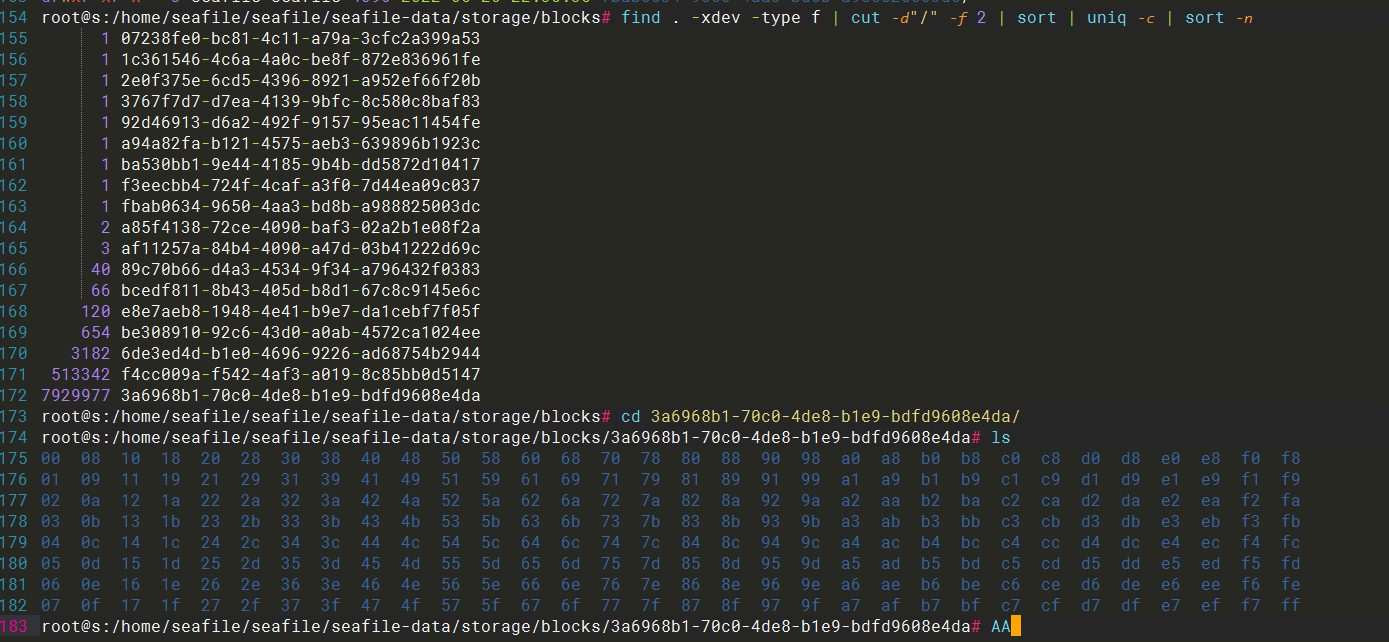
明显是出BUG了,blocks 对象没有正确处理,他一直在增长,不会被清理,短短几天内,文件数增加了几个图片,几十文件数量,我的 inode 增长了几十万,如图:
,并且issue里面已经有人指出了,里面的,回答 “The fs directory contains file system metadata for library. The number of
3天前的到现在增加了 16 个小图片文件,blocks 目录的 inode 增加 7万
希望尽快修复此类问题,服务器已重启,已关闭所有 历史版本,已清空所有回收站,已清空所有已删除的资料库,已重启 seafile,已进行 CG、FSCK 清理、检查,并重启服务器、seafile
无任何效果
现在开始使用
seaf-fsck.sh --export xxxxxx
导出资料库到本地文件系统的目录上,期间看到了一个报错,并且这个报错的资料库ID我是查不到的,我并没有这个资料库,不知道 blocks 异常持续增大是否与之有关,另外导出的文件大小也对不上,即使是 GiB和 GB的区别,也没到能差2个G的程度
我现在丢了什么文件都不知道
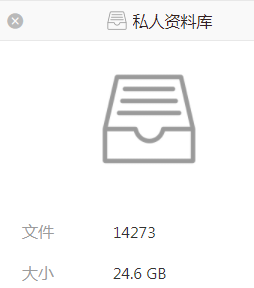
统计私人资料库导出的文件个数:
find -type f |wc -l
14271
与 seafile报告的 14273 不符,醉了
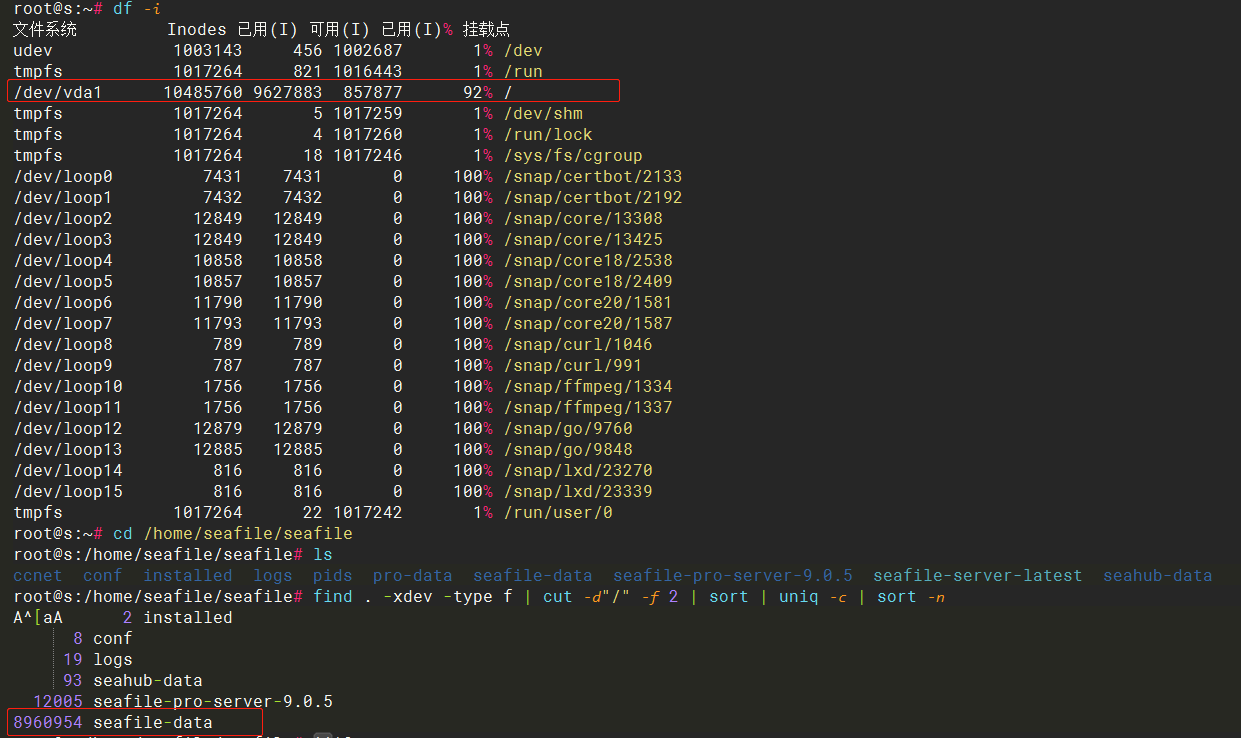
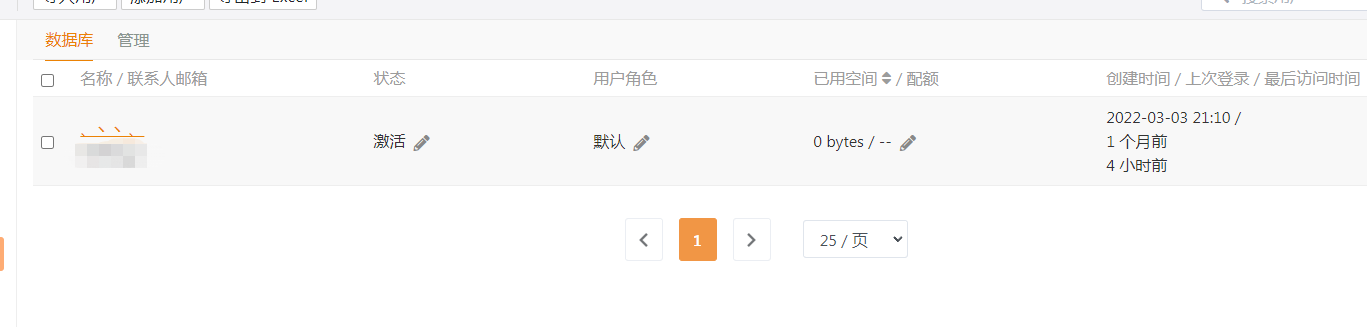
我删除了那 14273 个文件,即删除了那个 私人资料库文件,释放了 35 GB 空间,并清除所有资料库历史、回收站、资料库回收站,并运行了 GC,重启了 seafile 服务,结果 inode 仍然没有释放:
/dev/vda1 10485760 9645212 840548 92% /
转移完数据之后,我删除了 seafile 所有的资料库,并清空回收站、历史、资料库回收站,并确保只有我一个管理员账户,还运行了CG,重启 系统, seafile,空间并没有释放, inodes 也没有任何变化,现在已经更诡异了
执行GC脚本返回了什么 有没有打印出回收了多少空间呢?
没有打印出回收了多少空间,并且报了一个似乎python的语法错误,就xxx行xxx错误,但最后还是 finished 了,现在我已经重装seafile了,我按照官方中英文文档对比,备份数据库和seafile-data目录,重新部署,seahub服务在启动时报错 无法创建管理员,web前端界面无法访问,报 seafile Page unavailable,检查seahub.log,报了大量 python3 的错误,问题是服务器的环境并没有问题,最后直接删除数据和数据库,手动备份conf配置文件,重新安装seafile并迁移数据,才成功解决
我是从seafile 9.0.5升级到9.0.6 才出现这些问题的,出现之后重新部署9.0.6,导入备份的数据库和备份目录,前端无法工作
ubuntu 20.04.4 LTS,python 3.8.10,pip3 22.2.2
这个解释也不太合理,空间必须手动去运行CG才释放的?即使真的是这种设计,在没开历史版本,不怎么删除文件(一个月删除次数≤5),一个人使用,空间大小总量保持基本恒定的情况下,使用半年,blocks 一直增长也无论如何无法用 CG 清理来解释吧,这个量级的规模,能吃掉近千万 inodes,更别说其他人部署的seafile,恐怕几天文件系统就占满inode了,参照 github 2015年的issue,提问者的环境还比我的数据存储数量更少,文件规模更小
这是正常的,同样的数据量、目录结构层次不变,文件系统实际inode占用
11.3 万 inode,之前那个 860 万 +,无论如何都无法用 cg 清理解释,你们也不可能这么设计,我的情况还是一个人的非常轻量的使用场景
之前 rsync 清空 seafile-data 目录 都得使用 1个小时
现在已经重装无法复现了,不再讨论,作为给你们的一个样例,能复现能修再说了
keccak
2022 年9 月 22 日 10:20
14
a>使用了 Go 前端
针对 a,按文章说法改回去默认前端,针对 b 和 c,可以尝试先使用2个工具, fsck 和 fscg,分别用于检测资料库数据完整性和清理垃圾
这 2 个工具 只要有任意一个无法运行,或者运行时报错退出(python类的),或者 fsck 检测到损坏的资料库,并且修复后继续报同样的 ID 资料库损坏
然后备份相关 原先 seafile 配置,直接重装 seafile,删除原来的 seafile,恢复配置文件,使用 seaf-import - Seafile Cloud
应该能解决了,简单验证方法:运行fsck fscg 这2个工具,检查能否运行,且有无报错./seaf-gc.sh --rm-fs,能否运行成功,能运行成功说明 可以正确处理 fs 对象了
9711
2023 年1 月 17 日 02:14
15
把文件同步备份下来,然后新建一个资料库上传文件,删除旧的资料库清空回收站,服务器运行gc清空就会释放了,这是个bug,必须要删除整个资料库回收才会释放
keccak
2023 年6 月 22 日 08:21
16
该问题已经解决了,详见博客更新,必须导出到本地文件系统,备份 seafile 配置,重装 seafile,再导入数据
产生该 BUG 行为,推测是 Go 服务端不完善